Why LD Patch
The LDP Working Group recently published LD Patch, a format for describing changes to apply to Linked Data. It is suitable for use with HTTP PATCH, a method to perform partial modifications to Web resources.
After explaining the need for a PATCH format for Linked Data, I will go through all the other candidate technologies that the group considered, before explaining the rationale behind LD Patch. It is fair to remind the reader that the group is still eager for feedback, and that not all the group participants would agree with the views expressed in this post.
Genesis
Despite strong interest from the group participants in a way to partially update LDP Resources with HTTP PATCH, settling on which format to use proved to be more difficult than expected. The group could only agree on standardising the use of PATCH over POST, and decided to wait for concrete proposals while allowing the main specification to reach completion.
Work on a PATCH format for LDP got on a limbo for a while, and concretely resumed during the 5th LDP face-to-face in Boston, MA, where I presented all the proposals the group had gathered so far. I had completed the implementations of both Eric’s SparqlPatch and Pierre-Antoine’s rdfpatch in banana-rdf at that time. Those two proposals were for me the only two serious challengers.
A PATCH format for LDP
Enough talking. What do we even mean by a PATCH format for LDP? Consider the following RDF graph:
$ GET -S -H 'Accept: text/turtle' http://www.w3.org/People/Berners-Lee/card
200 OK
@prefix schema: <http://schema.org/> .
@prefix profile: <http://ogp.me/ns/profile#> .
@prefix ex: <http://example.org/vocab#> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
<http://www.w3.org/People/Berners-Lee/card#i> a schema:Person ;
schema:alternateName "TimBL" ;
profile:first_name "Tim" ;
profile:last_name "Berners-Lee" ;
schema:workLocation [ schema:name "W3C/MIT" ] ;
schema:performerIn _:b1, _:b2 ;
ex:preferredLanguages ( "en" "fr" ).
_:b1 schema:name "F2F5 - Linked Data Platform" ;
schema:url <https://www.w3.org/2012/ldp/wiki/F2F5> .
_:b2 a schema:Event ;
schema:name "TED 2009" ;
schema:startDate "2009-02-04" ;
schema:url <http://conferences.ted.com/TED2009/> .
Even if you are not well-versed in RDF and Turtle, I bet you can still understand that this piece of data is about a person named Tim Berners-Lee, identified by the URI <http://www.w3.org/People/Berners-Lee/card#i>. Also, TimBL seems to have been a participant in two events, each of them having some data attached to them. Also, do you see how those _:b1 and _:b2 identifiers give you more flexibility than plain JSON? They are identifiers local to this graph and are called blank nodes.
Other blank nodes get handled by the Turtle syntax, as you can see if you click on the following graph for a full-size visual representation of the data:
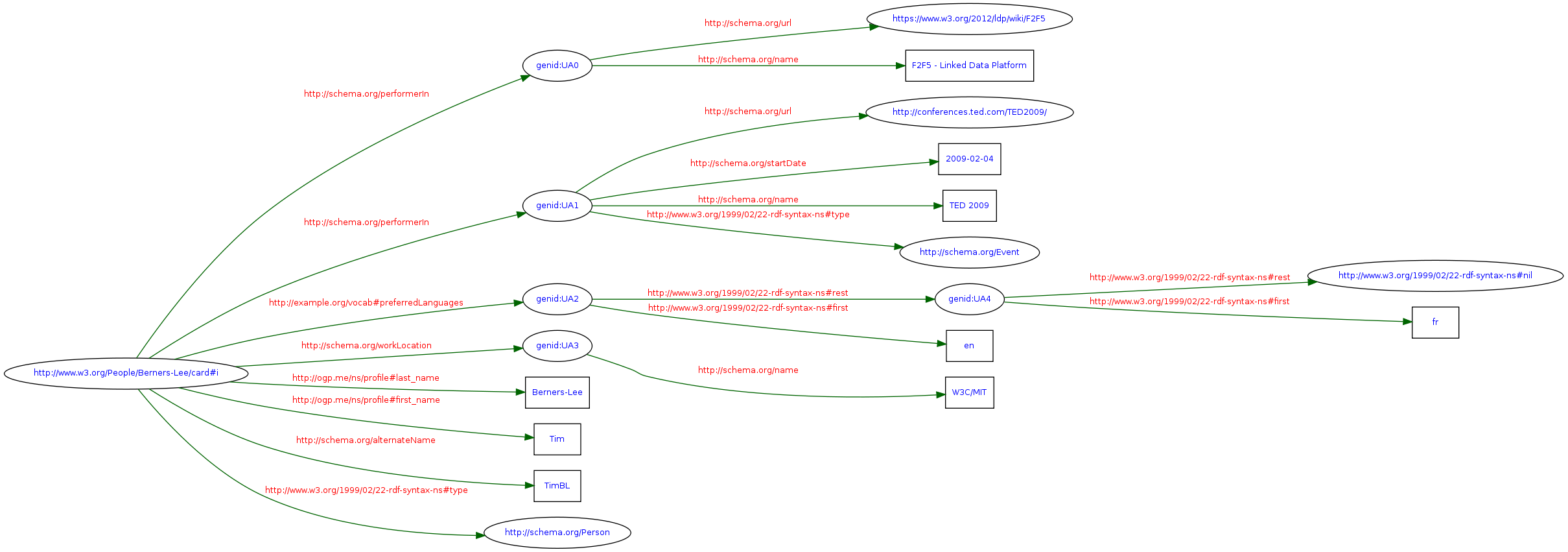
As a side note, let me bring your attention on the URIs being used here: they all resolve to actual documents on the Web, including the vocabularies from schema.org and Facebook’s Open Graph Protocol.
Now, let’s imagine that TimBL wants to add some geo coordinates to the TED event.
RDF Patch / TurtlePatch
Here is what TimBL could do with RDF Patch:
$ cat query.rdfp
Add _:b2 <http://schema.org/location> _:loc .
Add _:loc <http://schema.org/name> "Long Beach, California" .
Add _:loc <http://schema.org/geo> _:geo .
Add _:geo <http://schema.org/latitude> "33.7817" .
Add _:geo <http://schema.org/longitude> "-118.2054" .
$ cat query.rdfp | PATCH -S -c 'Content-Type: application/rdf-patch' http://www.w3.org/People/Berners-Lee/card
204 No Content
Well, this actually does not work.
Remember when I said that the blank node _:b2 was a local identifier for the graph? This means that TimBL cannot refer directly to the TED event from outside the document. That would require for the server and the client to agree on a stable identifier for that blank node. That process is called skolemization. It brings a lot of burden on the server to manage those stable identifiers. Also, while the use of blank nodes is mostly transparent in Turtle and JSON-LD as they are hidden in the syntax, skolemization would break the syntax.
TurtlePatch has similar expressive power compared to RDF Patch, but it is defined as a subset of SPARQL Update. It also defines skolemization as being part of the protocol, where the client can ask for a skolemized version of the graph, which would then be required before PATCHing.
Because blank nodes occur very frequently and skolemization was a no-go for several participants of the group, the results of one of the strawpolls we had on this subject were welcomed with surprise:
STRAWPOLL: I’d rather have a solution that (a) doesn’t address certain pathological graphs, or (b) requires the server to maintain Skolemization maps
The participants were largely in favor of (a), while (b) had basically no support. Knowing that, the group could now focus on alternative proposals, such as SparqlPatch.
SparqlPatch
SparqlPatch was proposed by Eric Prud’hommeaux, one of the editors for the SPARQL query language. SparqlPatch is a profile for SPARQL Update, as it is defined as a subset of it: a valid SparqlPatch query will always be a valid SPARQL Update query, sharing the same semantics.
Why not full SPARQL Update? Well, SPARQL Update comes with a complex machinery for matching nodes in a graph store. Complexity is never a bad thing when it is justified, which is the case for most SPARQL applications. But it is definitely overkill in the context of LDP, hence Eric’s proposal.
With SparqlPatch, TimBL would be able to update his profile using the following query:
$ cat query.sparql-patch
PREFIX schema: <http://schema.org/>
INSERT {
?ted <http://schema.org/location> _:loc .
_:loc <http://schema.org/name> "Long Beach, California" .
_:loc <http://schema.org/geo> _:geo .
_:geo <http://schema.org/latitude> "33.7817" .
_:geo <http://schema.org/longitude> "-118.2054" .
}
WHERE {
?ted schema:url <http://conferences.ted.com/TED2009/>
}
$ cat query.sparql-patch | PATCH -S -c 'Content-Type: text/sparqlpatch' http://www.w3.org/People/Berners-Lee/card
204 No Content
The WHERE clause binds the variable ?ted to the node that satisfies the schema:url constraint, and that variable can now be used to INSERT new triples.
This is definitely better and worth considering, as we now have a way to PATCH graphs with blank nodes. But this is still not perfect…
The runtime complexity for matching nodes in a graph is known to be extremely bad in some cases. While SparqlPatch is better that SPARQL Update in that regard, there are still some issues, which become apparent only when you start implementing and thinking about the runtime semantics. The main data structure in the SPARQL semantics is the Solution Mapping, which keeps track of which concrete nodes from the graph can be mapped to which variables, applying to each clause in the WHERE statement. So the semantics of the Basic Graph Pattern (ie. all the clauses in the SparqlPatch’s WHERE) involves a lot of costly cartesian products.
Also, it would be nice to change the evaluation semantics of the Basic Graph Pattern such that the evaluation order of the clauses is exactly the one from the query. It makes a lot of sense to let the client have some control over the evaluation order in the context of a PATCH.
SPARQL Update can also be confusing in that if a graph pattern doesn’t match anything, the query still succeeds with no effect on the graph. I have seen many engineers get puzzled by this (perfectly well defined) behaviour, because they were expecting the query to fail: this would happen every time a predicate gets typoed. I am jumping a bit ahead but that is one reason why LD Patch cannot be compiled down to SPARQL Update while preserving the semantics.
Finally, SparqlPatch has no support for rdf:lists. On one hand, SPARQL is heavily triple-focused and has never played very well with rdf:list. List matching improved in SPARQL 1.1 with Property Paths but their support is not native, in that common operations such as slice manipulation, update, or even a simple append, need to be encoded in the query.
On the other hand, lists are a common data structure in all applications. They come with native support in syntaxes like Turtle or JSON-LD. Append is a very common operation and the user should not have to think about the RDF list encoding for such simple operations.
Limited node matching capabilities and native rdf:list support are two features of LD Patch.
LD Patch
LD Patch was originally proposed by Pierre-Antoine Champin. The format described in the First Public Working Draft is very close to his original proposal. I became an editor for the specification to make some syntactical enhancements and to make sure that we could provide a clean formal semantics for it.
Pierre-Antoine maintains a Python implementation. On my side, I have a Scala implementation working with Jena, Sesame, and plain Scala. Andrei Sambra, the third editor, is working on Go and Javascript implementations.
A potential drawback for LD Patch is that some RDF graphs cannot be patched. They are deemed pathological and are very rare in practice: Linked Data applications should never be concerned. This may not be true for some SPARQL applications, but this is not our use-case here.
Let’s see what TimBL’s query would look like using LD Patch:
$ cat query.ld-patch
@prefix schema: <http://schema.org/> .
Bind ?ted <http://conferences.ted.com/TED2009/> / ^schema:url .
Add ?ted schema:location _:loc .
Add _:loc schema:name "Long Beach, California" .
Add _:loc schema:geo _:geo .
Add _:geo schema:latitude "33.7817" .
Add _:geo schema:longitude "-118.2054" .
$ cat query.ld-patch | PATCH -S -c 'Content-Type: text/ldpatch' http://www.w3.org/People/Berners-Lee/card
204 No Content
Unlike SparqlPatch, the Bind statement does not operate on triples. Instead, an LD Path expression (/ ^schema:url) is evaluated against a concrete starting node (<http://conferences.ted.com/TED2009/>). The result node gets bound to a variable (?ted) which can then be used in the following statements. That is the main difference when compared to SparqlPatch semantics.
Note: LD Path expressions are very similar to the JSON Pointers used in JSON Patch, and to the XPath selectors used in XML Patch.
The runtime semantics for LD Path expressions only rely on a node set. The final set must have a unique value to successfuly be bound to the variable, otherwise it results in an error. A path expression is processed from left to right, and can have nested paths for filtering nodes.
Given that semantics, you can imagine that it is 1. easy to reason about, 2. easy to implement, and 3. very efficient. I would even argue that you cannot remove functionalities from the path expressions without throwing away a whole class of interesting RDF graphs that LD Patch is able to patch.
Writing a parser for LD Patch proved to be of similar difficulty than for SparqlPatch, as they share most of their respective grammars with Turtle. Most of the code for the engine itself actually lies in the support for rdf:list, which basically encodes what users would have to do in their queries if they didn’t have native support for list manipulations. So this ends up being done in one place, once and for all, and that is indeed a very good thing.
The UpdateList operation is very similar to how slicing is done in Python. I invite you to read the corresponding section in the specification for more examples. LD Patch slicing is very intuitive and so far it has met no resistance in the Working Group.
Subjectivity
It took a very long time before the group was able to publish LD Patch. I still regret that any opportunity would be taken by few people to challenge the whole technology, often without even providing which requirements they would like to address.
For example, the main criticism seems to be about the syntax. Yes, it is a new one, even though 68% of the grammar is shared with Turtle. In particular, it is different from the SPARQL Update syntax. But apparently, it doesn’t matter to some folks if the semantics are not the same.
I have many, many times given my list of requirements (it is not only mine: those requirements are of course shared by others) on the LDP mailing list but somehow, they were never really challenged, and the arguments about syntax keep coming back. So for the record, here they are:
- the context is Linked Data, and especially the Linked Data Platform
- bare minimum for LDP Resource diff, that is, no high-level features
- support for blank nodes, but pathological graphs are ok
- no skolemization
- first-class citizen
rdf:listmanipulations - reasonable runtime complexity
- easy to implement without the need for an existing SPARQL Update implementation
- not being able to bind a node is a failure
- being a reasonable alternative for the JSON-LD folks using JSON Patch, because they don’t have better
If you want to make counter proposals, please make sure that those requirements are addressed. Also, you should accept the fact that if you have a different set of requirements, then LD Patch is probably not what you want. Finally, if you think that the above requirements are wrong in the context of LDP, then you should make an official complaint to the group explaining your reasoning.
I would like to emphasize that relying on an existing syntax (such as SPARQL) was never a requirement for me. While reusing bits of SPARQL Update in LD Patch whenever it makes sense is reasonable, it should be done sparingly. For example, I argued on the LDP mailing list that shared syntax with different (runtime) semantics could break some user expectations.
Frequently Asked Questions
Thanks to David Booth for providing me with well formulated questions and concerns. Here are some answers. They only complete the arguments in the other sections of this post.
Are there any concerns about inventing a new syntax? What if SPARQL, or a profile of it, could not address all the requirements? What if a subset of the syntax was no longer aligned with the superset semantics?
Isn’t this yet another syntax similar to SPARQL, which ends up confusing newcomers? Of course there are similar: exactly 68% of the grammar rules for LD Patch are directly coming from Turtle, and SPARQL made a similar choice.
Would using a single language decrease development and maintenance costs? I would like to see actual evidence of that claim. Some people actually have a more nuanced opinion on that subject, and I tend to agree as I find myself using the language/framework that I find the most fit to a given job.
Can implementers simply plug in an existing general-purpose SPARQL engine to get a new system up and running quickly? Not so easy. You still need to reject the valid SPARQL Update queries that are not valid LD Patch queries. And you can be sure that I will make sure that the test suite has tests for that :-) And because I have done it, I can claim that unlike full SPARQL, LD Patch is quick and easy to implement.
Would implementers have the option of supporting additional SPARQL 1.1 Update operations? There is definitely a use-case for querying data in LDP Containers using SPARQL, or using a more ad-hoc query language with support for ordering, filtering, and aggregation. And it is true that bulk updating could be addressed with SPARQL Update. But those use-cases are different from PATCH.
Next steps
The First Public Working Draft just got published. As expected, the document is getting reviewed by experts, who have already started to provide feedback to the group.
In the meantime, the editors are working on completing the semantics section of the document. A proposed approach was to provide a translation from LD Patch to SPARQL Update. While this is definitely useful for people with a SPARQL background, this cannot be used as a formal semantics. We are trying to find a good trade-off between the usual tooling from formal semantics theory, and something that could be read by people without such a theoretical background.
And finally, after the specification gets completed, we will focus on providing a test suite. The plan is to make it part of the LDP one.
That’s all folks. (and thanks Andrei for reviewing drafts for this post)