class: center, middle # Web Frames ## data architecture notes --- ## from CSV ``` $ cat salesData.csv quarter,days,sales 2011-Q1,92,1200 2011-Q2,92,1250 2011-Q3,90,1350 2011-Q4,91,1255 ``` ``` $ curl -X PUT \ -H 'Content-Type: text/csv' \ -d @salesData.csv \ https://example.com/salesData ``` --- ## as Turtle ``` $ curl -X GET -H 'Accept: text/turtle' https://example.com/salesData @prefix f: <http://data.pellucid.org/ns/frame#> . <> a f:Frame ; f:series <#quarter>, <#days>, <#sales> . <#quarter> a f:Series ; f:cells <#c11>, <#c12>, <#c13>, <#c14> . <#c11> a f:Cells ; f:index 0 ; f:item "2011-Q1" . <#c12> a f:Cells ; f:index 1 ; f:item "2011-Q2" . <#c13> a f:Cells ; f:index 2 ; f:item "2011-Q3" . <#c14> a f:Cells ; f:index 3 ; f:item "2011-Q4" . <#days> a f:Series ; f:cells <#c21>, <#c22>, <#c23>, <#c24> . <#c21> a f:Cells ; f:index 0 ; f:item "92" . <#c22> a f:Cells ; f:index 1 ; f:item "92" . <#c23> a f:Cells ; f:index 2 ; f:item "90" . <#c24> a f:Cells ; f:index 3 ; f:item "91" . <#sales> a f:Series ; f:cells <#c31>, <#c32>, <#c33>, <#c34> . <#c31> a f:Cells ; f:index 0 ; f:item "1200" . <#c32> a f:Cells ; f:index 1 ; f:item "1250" . <#c33> a f:Cells ; f:index 2 ; f:item "1350" . <#c34> a f:Cells ; f:index 3 ; f:item "1255" . ``` --- ## graphical representation .img100[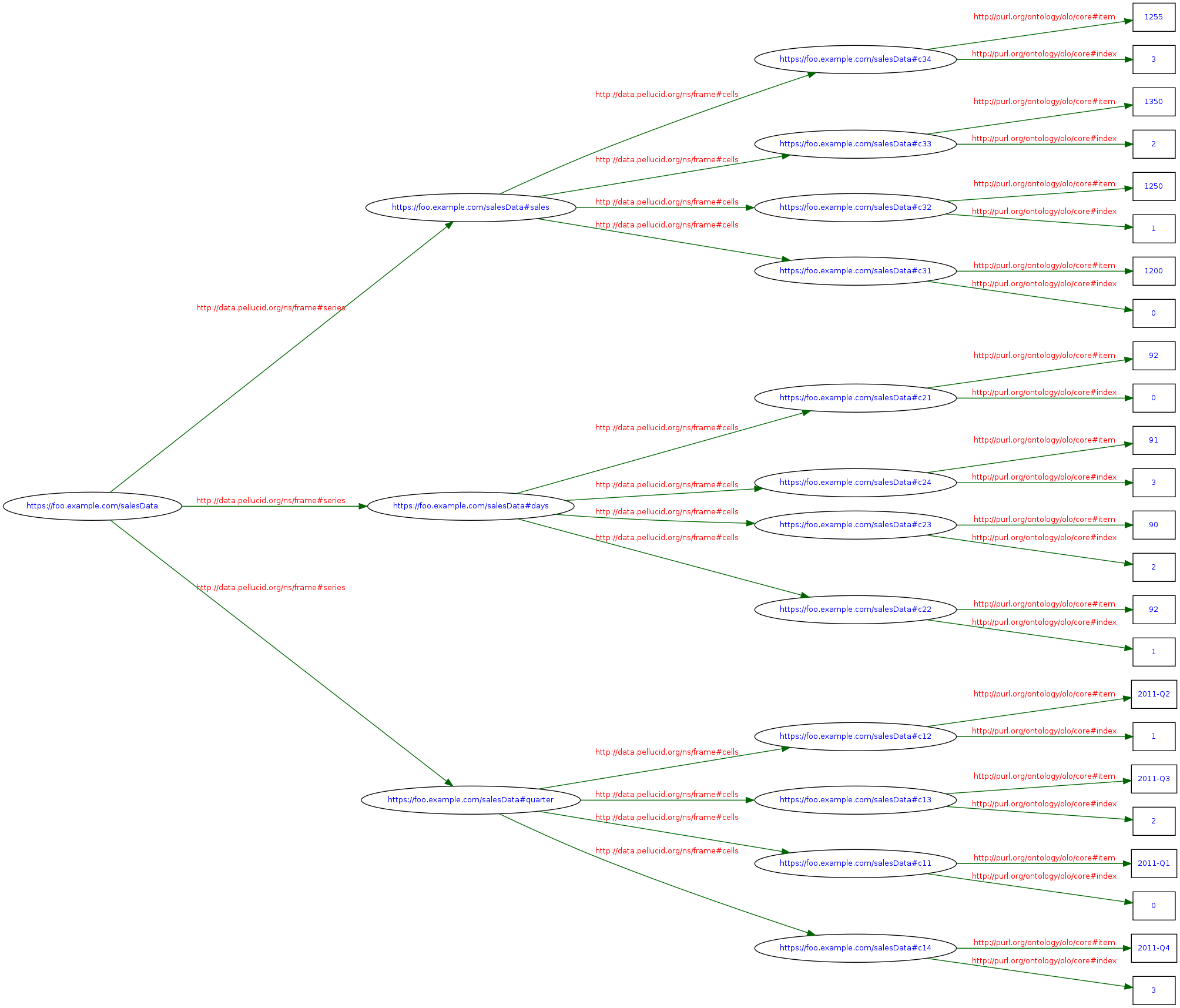] --- ## denoting things ### denoting a frame on the Web https://example.com/salesData ### denoting a series in a frame https://example.com/salesData#quarters ### denoting a cell in a frame https://example.com/salesData#c21 ### note names are meaningless! --- ## reusing data ``` $ curl -X GET -H 'Accept: text/turtle' https://example.com/tomsSalesData @prefix f: <http://data.pellucid.org/ns/frame#> . <> a f:Frame ; f:series <https://example.com/salesData#quarter>, <#days>, <#sales> . <#days> f:extends <https://example.com/salesData#days> . <#sales> f:extends <https://example.com/salesData#sales> ; f:overrides <#newCell31> . <#newCell31> a f:Cells ; f:index 1 ; f:item "1257" . ``` typically constructed through web-interface ### features * data reusability * overriding * explicit provenance * implicit data dependencies --- ## architecture * datasource: Web * no distinction between private/public data * CSV: RDF mapping * Datomic: RDF mapping * other databases: RDF mapping * updates * pull on dependencies, or ask for diffs * dependencies push diffs * Akka Persistence? * access control: resource-based. Play well with HTTP. * caching: per resource. Plays well with HTTP. --- ### granularity * https://example.com/salesData#quarters <br> vs https://example.com/salesData/quarters * → query language + inlining * has impact on caching ### sending data on the wire * for humans/debugging: Turtle * for machines/performance: HDT http://www.rdfhdt.org/what-is-hdt/ ### protocol * REST interaction model already defined: Linked Data Platform (aka. LDP) * exchanging diffs being defined: LD Patch * pingback mechanism not yet defined * have some ideas based on work w/ TimBL's team at MIT * is on charter for LDP 2 * WebSocket + HDT + LD Patch? --- ## not discussed * controlled entities for column indexes * data/metadata * versioning